Why use Instructor?¶
This is a letter from the author Jason Liu of Instructor. I'm a big fan of Pydantic and I think it's the best way to handle data validation in Python. I've been using it for years and I'm excited to bring it to the OpenAI API.
Why use Pydantic?
Its hard to answer the question of why use Instructor without first answering why use Pydantic.:
-
Powered by type hints — with Pydantic, schema validation and serialization are controlled by type annotations; less to learn, less code to write, and integration with your IDE and static analysis tools.
-
Speed — Pydantic's core validation logic is written in Rust. As a result, Pydantic is among the fastest data validation libraries for Python.
-
JSON Schema — Pydantic models can emit JSON Schema, allowing for easy integration with other tools. [Learn more…]
-
Customisation — Pydantic allows custom validators and serializers to alter how data is processed in many powerful ways.
-
Ecosystem — around 8,000 packages on PyPI use Pydantic, including massively popular libraries like FastAPI, huggingface, Django Ninja, SQLModel, & LangChain.
-
Battle tested — Pydantic is downloaded over 70M times/month and is used by all FAANG companies and 20 of the 25 largest companies on NASDAQ. If you're trying to do something with Pydantic, someone else has probably already done it.
No New standards¶
Instructor is built on top of Pydantic and OpenAI, which will be familiar to many developers already. But, since many llm providers support the OpenAI API spec, you can use many closed source and open source providers like Anyscale, Together, Groq, Ollama, and Llama-cpp-python.
All we do is augment the create such that
Check out how we connect with open source
Pydantic over Raw Schema¶
I find many prompt building tools to be overly complex and difficult to use, they might be simple to get started with a trivial examples but once you need more control, you have to wish they were simpler. Instructor does the least amount of work to get the job done.
Pydantic is more readable and definitions and reference values are handled automatically. This is a big win for Instructor, as it allows us to focus on the data extraction and not the schema.
from typing import List, Literal
from pydantic import BaseModel, Field
class Property(BaseModel):
name: str = Field(description="name of property in snake case")
value: str
class Character(BaseModel):
"""
Any character in a fictional story
"""
name: str
age: int
properties: List[Property]
role: Literal['protagonist', 'antagonist', 'supporting']
class AllCharacters(BaseModel):
characters: List[Character] = Field(description="A list of all characters in the story")
Would you Ever prefer to code review this? Where everything is a string, ripe for typos and errors in references? I know I wouldn't.
var = {
"$defs": {
"Character": {
"description": "Any character in a fictional story",
"properties": {
"name": {"title": "Name", "type": "string"},
"age": {"title": "Age", "type": "integer"},
"properties": {
"type": "array",
"items": {"$ref": "#/$defs/Property"},
"title": "Properties",
},
"role": {
"enum": ["protagonist", "antagonist", "supporting"],
"title": "Role",
"type": "string",
},
},
"required": ["name", "age", "properties", "role"],
"title": "Character",
"type": "object",
},
"Property": {
"properties": {
"name": {
"description": "name of property in snake case",
"title": "Name",
"type": "string",
},
"value": {"title": "Value", "type": "string"},
},
"required": ["name", "value"],
"title": "Property",
"type": "object",
},
},
"properties": {
"characters": {
"description": "A list of all characters in the story",
"items": {"$ref": "#/$defs/Character"},
"title": "Characters",
"type": "array",
}
},
"required": ["characters"],
"title": "AllCharacters",
"type": "object",
}
Easy to try and install¶
The minimum viable api just adds response_model to the client, if you dont think you want a model its very easy to remove it and continue building your application
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Patch the OpenAI client with Instructor
client = instructor.from_openai(OpenAI())
class UserDetail(BaseModel):
name: str
age: int
# Function to extract user details
def extract_user() -> UserDetail:
user = client.chat.completions.create(
model="gpt-4-turbo-preview",
response_model=UserDetail,
messages=[
{"role": "user", "content": "Extract Jason is 25 years old"},
]
)
return user
import openai
import json
def extract_user() -> dict:
completion = client.chat.completions.create(
model="gpt-4-turbo-preview",
tools=[
{
"type": "function",
"function": {
"name": "ExtractUser",
"description": "Correctly extracted `ExtractUser` with all the required parameters with correct types",
"parameters": {
"properties": {
"name": {"title": "Name", "type": "string"},
"age": {"title": "Age", "type": "integer"},
},
"required": ["age", "name"],
"type": "object",
},
},
}
],
tool_choice={"type": "function", "function": {"name": "ExtractUser"}},
messages=[
{"role": "user", "content": "Extract Jason is 25 years old"},
],
) # type: ignore
user = json_loads(completion.choices[0].message.tool_calls[0].function.arguments)
assert "name" in user, "Name is not in the response"
assert "age" in user, "Age is not in the response"
user["age"] = int(user["age"])
return user
Partial Extraction¶
We also support partial extraction, which is useful for streaming in data that is incomplete.
import instructor
from instructor import Partial
from openai import OpenAI
from pydantic import BaseModel
from typing import List
from rich.console import Console
client = instructor.from_openai(OpenAI())
text_block = "..."
class User(BaseModel):
name: str
email: str
twitter: str
class MeetingInfo(BaseModel):
users: List[User]
date: str
location: str
budget: int
deadline: str
extraction_stream = client.chat.completions.create(
model="gpt-4",
response_model=Partial[MeetingInfo],
messages=[
{
"role": "user",
"content": f"Get the information about the meeting and the users {text_block}",
},
],
stream=True,
)
console = Console()
for extraction in extraction_stream:
obj = extraction.model_dump()
console.clear()
console.print(obj)
This will output the following:
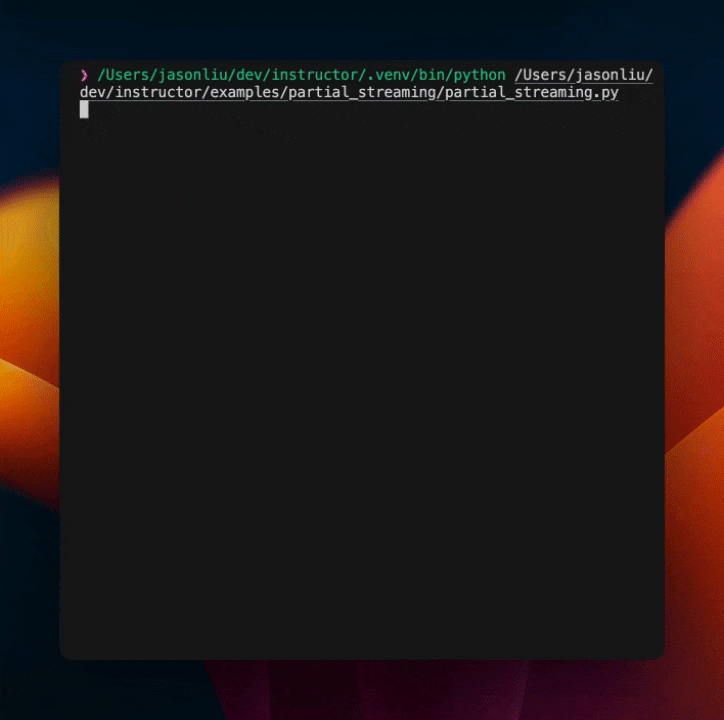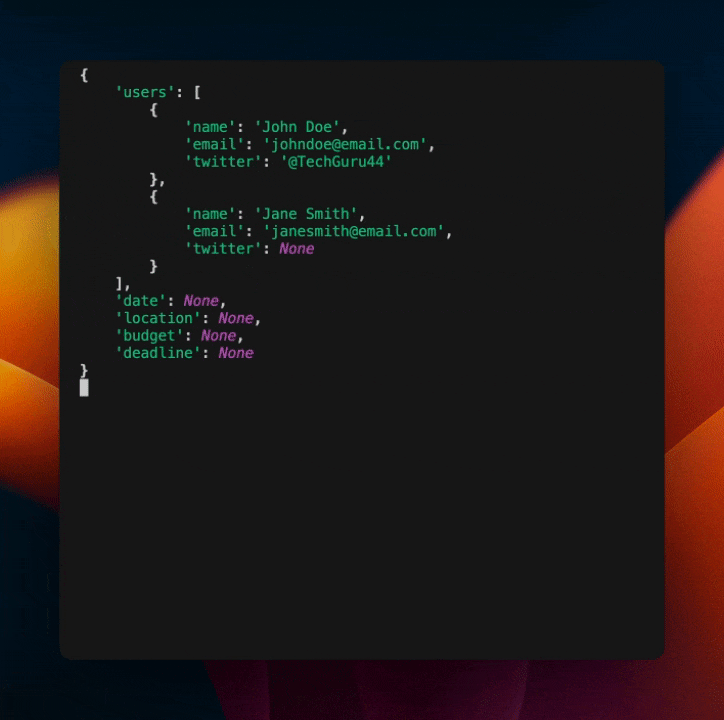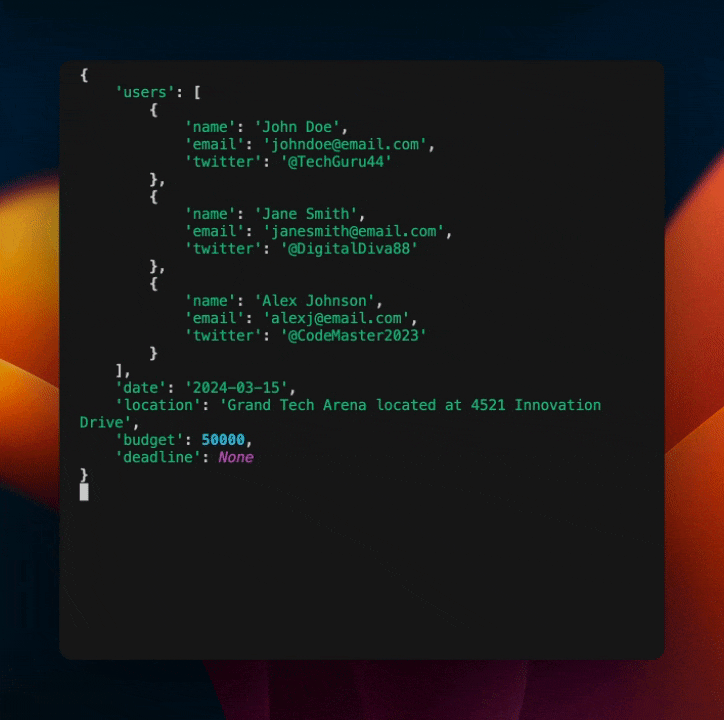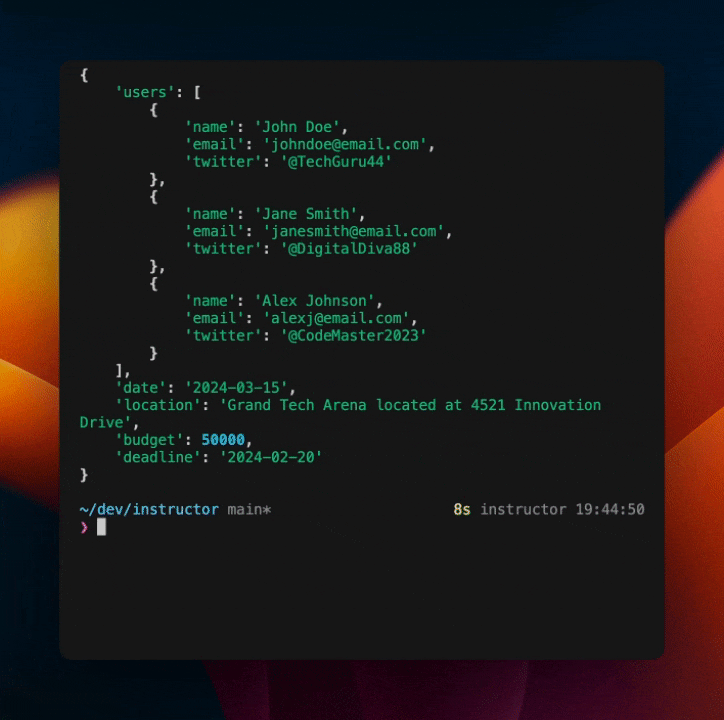
As you can see, we've baked in a self correcting mechanism into the model. This is a powerful way to make your models more robust and less brittle without including a lot of extra code or prompts.
Iterables and Lists¶
We can also generate tasks as the tokens are streamed in by defining an Iterable[T] type.
Lets look at an example in action with the same class
from typing import Iterable
Users = Iterable[User]
users = client.chat.completions.create(
model="gpt-4",
temperature=0.1,
stream=True,
response_model=Users,
messages=[
{
"role": "system",
"content": "You are a perfect entity extraction system",
},
{
"role": "user",
"content": (
f"Consider the data below:\n{input}"
"Correctly segment it into entitites"
"Make sure the JSON is correct"
),
},
],
max_tokens=1000,
)
for user in users:
assert isinstance(user, User)
print(user)
#> name="Jason" "age"=10
#> name="John" "age"=10
Simple Types¶
We also support simple types, which are useful for extracting simple values like numbers, strings, and booleans.
Self Correcting on Validation Error¶
Due to pydantic's very own validation model, easily add validators to the model to correct the data. If we run this code, we will get a validation error because the name is not in uppercase. While we could have included a prompt to fix this, we can also just add a field validator to the model. This will result in two API calls, to make sure you do your best to prompt before adding validators.
import instructor
from openai import OpenAI
from pydantic import BaseModel, field_validator
# Apply the patch to the OpenAI client
client = instructor.from_openai(OpenAI())
class UserDetails(BaseModel):
name: str
age: int
@field_validator("name")
@classmethod
def validate_name(cls, v):
if v.upper() != v:
raise ValueError("Name must be in uppercase.")
return v
model = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=UserDetails,
max_retries=2,
messages=[
{"role": "user", "content": "Extract jason is 25 years old"},
],
)
assert model.name == "JASON"