Structured Outputs with llama-cpp-python¶
If you want to try this example using instructor hub, you can pull it by running
Open-source LLMS are gaining popularity, and llama-cpp-python has made the llama-cpp model available to obtain structured outputs using JSON schema via a mixture of constrained sampling and speculative decoding. They also support a OpenAI compatible client, which can be used to obtain structured output as a in process mechanism to avoid any network dependency.
Patching¶
Instructor's patch enhances an create call it with the following features:
response_modelincreatecalls that returns a pydantic modelmax_retriesincreatecalls that retries the call if it fails by using a backoff strategy
Learn More
To learn more, please refer to the docs. To understand the benefits of using Pydantic with Instructor, visit the tips and tricks section of the why use Pydantic page. If you want to check out examples of using Pydantic with Instructor, visit the examples page.
llama-cpp-python¶
Recently llama-cpp-python added support for structured outputs via JSON schema mode. This is a time-saving alternative to extensive prompt engineering and can be used to obtain structured outputs.
In this example we'll cover a more advanced use case of JSON_SCHEMA mode to stream out partial models. To learn more partial streaming check out partial streaming.
import llama_cpp
from llama_cpp.llama_speculative import LlamaPromptLookupDecoding
import instructor
from pydantic import BaseModel
from typing import List
from rich.console import Console
llama = llama_cpp.Llama(
model_path="../../models/OpenHermes-2.5-Mistral-7B-GGUF/openhermes-2.5-mistral-7b.Q4_K_M.gguf",
n_gpu_layers=-1,
chat_format="chatml",
n_ctx=2048,
draft_model=LlamaPromptLookupDecoding(num_pred_tokens=2), # (1)!
logits_all=True,
verbose=False,
)
create = instructor.patch(
create=llama.create_chat_completion_openai_v1,
mode=instructor.Mode.JSON_SCHEMA, # (2)!
)
text_block = """
In our recent online meeting, participants from various backgrounds joined to discuss
the upcoming tech conference. The names and contact details of the participants were as follows:
- Name: John Doe, Email: johndoe@email.com, Twitter: @TechGuru44
- Name: Jane Smith, Email: janesmith@email.com, Twitter: @DigitalDiva88
- Name: Alex Johnson, Email: alexj@email.com, Twitter: @CodeMaster2023
During the meeting, we agreed on several key points. The conference will be held on March 15th, 2024,
at the Grand Tech Arena located at 4521 Innovation Drive. Dr. Emily Johnson, a renowned AI researcher,
will be our keynote speaker.
The budget for the event is set at $50,000, covering venue costs, speaker fees, and promotional activities.
Each participant is expected to contribute an article to the conference blog by February 20th.
A follow-up meetingis scheduled for January 25th at 3 PM GMT to finalize the agenda and confirm the list of speakers.
"""
class User(BaseModel):
name: str
email: str
twitter: str
class MeetingInfo(BaseModel):
users: List[User]
date: str
location: str
budget: int
deadline: str
extraction_stream = create(
response_model=instructor.Partial[MeetingInfo], # (3)!
messages=[
{
"role": "user",
"content": f"Get the information about the meeting and the users {text_block}",
},
],
stream=True,
)
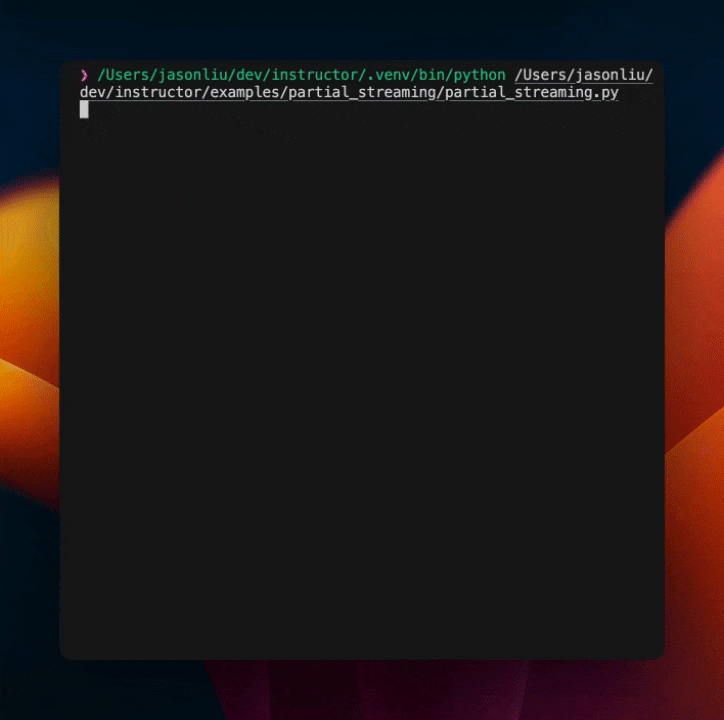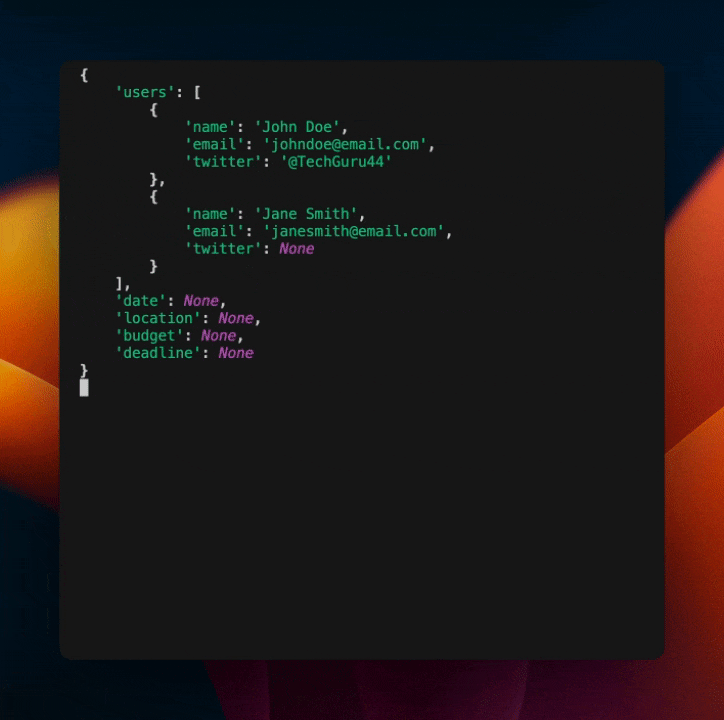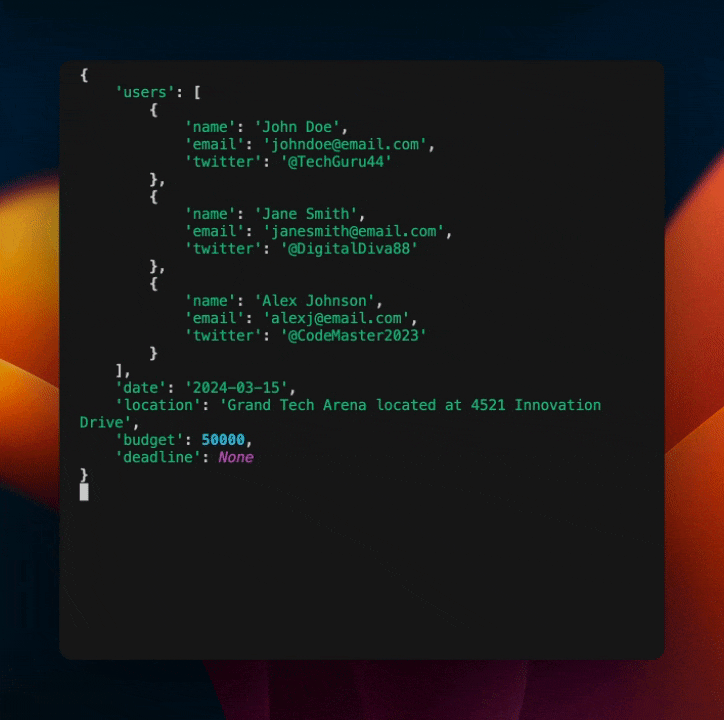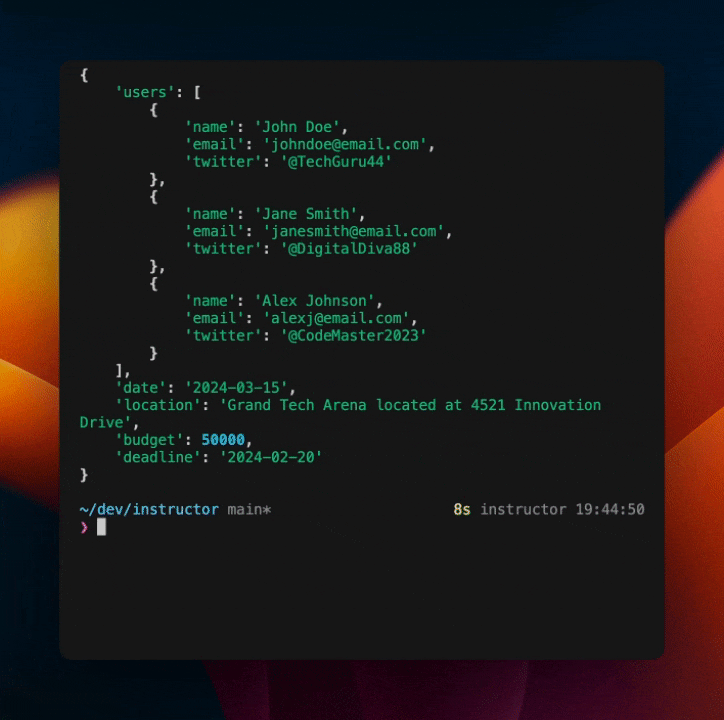
console = Console()
for extraction in extraction_stream:
obj = extraction.model_dump()
console.clear() # (4)!
console.print(obj)
We use LlamaPromptLookupDecoding to speed up structured output generation using speculative decoding. The draft model generates candidate tokens during generation 10 is good for GPU, 2 is good for CPU. 2. We use instructor.Mode.JSON_SCHEMA return a JSON schema response. 3. We use instructor.Partial to stream out partial models. 4. This is just a simple example of how to stream out partial models and clear the console.